
Ask any engineer and he’d agree – With growth, comes performance & scale challenges. Instamojo is no different. At the rate we are growing, we did face more than a few hiccups over time.
December 2013
Our only source of knowing the performance is Google Analytics for page load time. An average load time of 18s is not good at all. We believed it is time we include performance into our core priorities. The first basic rule of performance – Measure, and New Relic fits our bill perfectly with our stack.
At this time, our average server response time is approximately 370ms. But many outliers are crossing 30secs too. In the next 2 months, we fine-tuned our integration with New Relic. This was done to identify proper bottlenecks whenever and wherever we can.
Feb 2014
It was time to act upon the insights we got from the performance analysis from New Relic & Google Analytics.
1. Optimize database queries a lot. In terms of Django, we started effectively using `prefetch_related` and `select_related` and adding proper indexes to our database tables.
2. Use CDN for our static resources instead of serving directly from S3. While this is easy to set up, we still need a solution to avoid cache validation. Luckily django.contrib.staticfiles.storage.CachedStaticFilesStorage with some fixes worked like charm. It helped in generating hashed file paths for each of our files. For example, we have favicon.6b5a70e7628d.png generated from favicon.png. This can be cached by CDN as well as browser forever, without having to deal with cache-invalidation at all.
3. Support gzipped static assets. We made a trade-off here not to support non-gzipped static assets, given that most (and all modern) browsers support gzip compression.
We also observed some serious memory leaks with our Django application. They were causing memory thrashing and causing the slowdown.
June 2014
Our servers are much more predictable now. While we couldn’t totally fix the memory leaks, we mitigated the effects, and have workarounds in place. We started distributing our various services (both internal and external) into separate servers. This is to ensure they have minimal impact on each other.
How are we doing today?
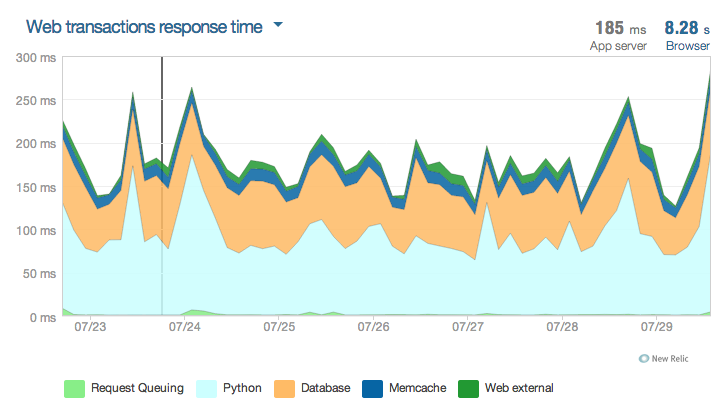
For the last 7 days (from New Relic):
Simplest Lessons:-
1. Invariability: You can’t fix the problems that you don’t know of.
2. Scalability: Design your systems for horizontal scalability. You’ll outgrow a single server, however big the server might be. It’s only a question of when.
3. Measure and Monitor: It is also important to monitor and measure the performance of all 3rd party services/modules. (I’m looking at you, sorl-thumbnail)
4. Improving performance is a continuous process: We have come a long way but we still have a long way ahead. Join us and help us beat rocket speed.
This post was penned by Sai Prasad, Head of Backend Engineering at Instamojo.com.